











Great offers on Summer Rugs
We have a large range Summer rugs, sizes 2'9" to 7'3", standard or full neck
Trending Products
-
![Picture of Gallop Gateley Waterproof Long Country Boots Leather, Walking, Casual, Riding,]() Vendor:GallopGallop Gateley Waterproof Long Country Boots Leather, Walking, Casual, Riding,
Vendor:GallopGallop Gateley Waterproof Long Country Boots Leather, Walking, Casual, Riding,- Regular price
- £62.95
- Regular price
-
- Sale price
- £62.95
- Unit price
- per
These high quality cow hide waterproof leather Gateley Country boots come in a choice of standard or wide calves and have a lace up side for extra flexibility. Our Gateley Boots are lined with a wa... -
![Picture of Jod Boots | Supreme Products Show Ring Short / Jodhpur Riding Boots | Oxblood]() Vendor:SupremeJod Boots | Supreme Products Show Ring Short / Jodhpur Riding Boots | Oxblood
Vendor:SupremeJod Boots | Supreme Products Show Ring Short / Jodhpur Riding Boots | Oxblood- Regular price
- £39.99
- Regular price
-
- Sale price
- £39.99
- Unit price
- per
Supreme Products Show Ring Jodhpur Boots are a classic, oxblood showing boot. These full grain leather jodhpur boots have been crafted using the finest form of material and were designed with show... -
![Picture of Science Supplements ProKalm Horse Calmer, Reduces Stress Anxiety, Syringe/Powder]()
![Picture of Science Supplements ProKalm Horse Calmer, Reduces Stress Anxiety, Syringe/Powder]() Vendor:Science SupplementsScience Supplements ProKalm Horse Calmer, Reduces Stress Anxiety, Syringe/Powder
Vendor:Science SupplementsScience Supplements ProKalm Horse Calmer, Reduces Stress Anxiety, Syringe/Powder- Regular price
- £12.99
- Regular price
-
- Sale price
- £12.99
- Unit price
- per
This product from Science Supplements is an innovation in managing stress and anxiety in horses allowing them to perform at their potential. Rapid acting and effective calming supplement with resul... -
![Picture of Gallop Elegence Leather Jodhpur Boots Horse Riding Short Boots, Black or Brown]()
![Picture of Gallop Elegence Leather Jodhpur Boots Horse Riding Short Boots, Black or Brown]() Vendor:GallopGallop Elegence Leather Jodhpur Boots Horse Riding Short Boots, Black or Brown
Vendor:GallopGallop Elegence Leather Jodhpur Boots Horse Riding Short Boots, Black or Brown- Regular price
- £25.99
- Regular price
-
- Sale price
- £25.99
- Unit price
- per
These Elegance short boots feature a unique SCP thread pattern for excellent footing both on the ground and in the stirrup. These boots take comfort to a whole new level with the raised arch and th...






-
![Picture of Shires Aubrion Equipt Horse Passport Holder, Hardwearing]() Vendor:ShiresShires Aubrion Equipt Horse Passport Holder, Hardwearing
Vendor:ShiresShires Aubrion Equipt Horse Passport Holder, Hardwearing- Regular price
- £6.25
- Regular price
-
- Sale price
- £6.25
- Unit price
- per
Protect your horse documents in the smart Aubrion Equipt passport holder. Paperwork stays clean and organised, a wipe clean see through window gives a clear view of the contents. Touch close closur... -
![Picture of Saddle Bag | Shires Aubrion Equipt Saddle Storage Bag, Hardwearing]() Vendor:ShiresSaddle Bag | Shires Aubrion Equipt Saddle Storage Bag, Hardwearing
Vendor:ShiresSaddle Bag | Shires Aubrion Equipt Saddle Storage Bag, Hardwearing- Regular price
- £36.89
- Regular price
-
- Sale price
- £36.89
- Unit price
- per
Transport your saddle easily and safely with the protective Aubrion Equipt carry bag. Outer padding protects against bumps and scratches. Opens out flat for convenience with a two way zip, grab han... -
![Picture of Bum Bag | Shires Aubrion Equipt Waist Bum Bag, Hardwearing]() Vendor:ShiresBum Bag | Shires Aubrion Equipt Waist Bum Bag, Hardwearing
Vendor:ShiresBum Bag | Shires Aubrion Equipt Waist Bum Bag, Hardwearing- Regular price
- £12.99
- Regular price
-
- Sale price
- £12.99
- Unit price
- per
Keep all your essentials to hand in the useful Aubrion Equipt bum bag. The two way zip opening gives easy access to ample storage space. Adjustable waist strap with clip and Aubrion logo. Dimensio... -
![Picture of Grooming Bag | Shires Aubrion Equipt Large Grooming Kit Storage Bag, Hardwearing]() Vendor:ShiresGrooming Bag | Shires Aubrion Equipt Large Grooming Kit Storage Bag, Hardwearing
Vendor:ShiresGrooming Bag | Shires Aubrion Equipt Large Grooming Kit Storage Bag, Hardwearing- Regular price
- £25.19
- Regular price
-
- Sale price
- £25.19
- Unit price
- per
A roomy and durable, the Aubrion Equipt grooming bag keeps all your grooming equipment tidy and organised. A zip opening lid keeps everything contained while on the move, the wipe clean inside offe...




-
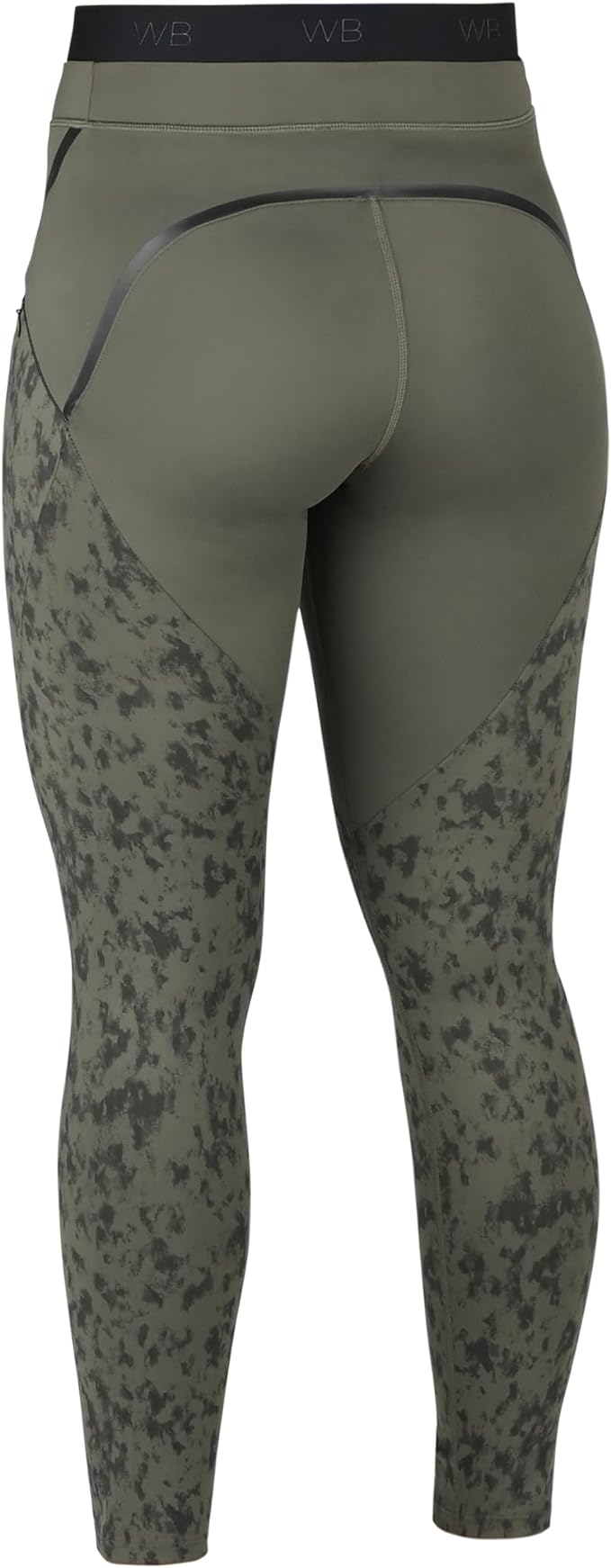
![Picture of Weatherbeeta Toulon Lifestyle Ladies Horse Riding Tights, Womens, 3 Colours]()
![Weatherbeeta Toulon Lifestyle Ladies Horse Riding Tights, Womens, 3 Colours]() Vendor:WeatherbeetaWeatherbeeta Toulon Lifestyle Ladies Horse Riding Tights, Womens, 3 Colours
Vendor:WeatherbeetaWeatherbeeta Toulon Lifestyle Ladies Horse Riding Tights, Womens, 3 Colours- Regular price
- £59.99
- Regular price
-
- Sale price
- £59.99
- Unit price
- per
The WeatherBeeta Toulon Lifestyle Tights are a technical lifestyle riding tight with inleg seams a great for everyday activity at the yard, gym, and more. The powerful, high denier interlock perfor... -
![Picture of Weatherbeeta Ladies Rome Short Sleeve Riding Top, Lightweight, Womens Size XS-XL]()
![Weatherbeeta Ladies Rome Short Sleeve Riding Top, Lightweight, Womens Size XS-XL]() Vendor:WeatherbeetaWeatherbeeta Ladies Rome Short Sleeve Riding Top, Lightweight, Womens Size XS-XL
Vendor:WeatherbeetaWeatherbeeta Ladies Rome Short Sleeve Riding Top, Lightweight, Womens Size XS-XL- Regular price
- £44.99
- Regular price
-
- Sale price
- £44.99
- Unit price
- per
The WeatherBeeta Roma Short Sleeve Riding Top is a technical base layer for everyday training and activity with 4-way stretch fabric for all day comfort. Great to coordinate and follow the Matchy M... -
![Picture of Weatherbeeta Ladies London Layer Long Sleeve Top, Lightweight, Womens Size XS-XL]()
![Weatherbeeta Ladies London Layer Long Sleeve Top, Lightweight, Womens Size XS-XL]() Vendor:WeatherbeetaWeatherbeeta Ladies London Layer Long Sleeve Top, Lightweight, Womens Size XS-XL
Vendor:WeatherbeetaWeatherbeeta Ladies London Layer Long Sleeve Top, Lightweight, Womens Size XS-XL- Regular price
- £39.99
- Regular price
-
- Sale price
- £39.99
- Unit price
- per
The London Layer long Sleeve Top is made from a comfortable brushed poly viscose elastane fabric ?ú perfect for layering. This essential WeatherBeeta top is made for riding and casual active wear. ... -
Vendor:WeatherbeetaWeatherbeeta Waterproof Ladies Jackson Jacket, Lightweight, Womens Size XS-XL,
- Regular price
- £89.99
- Regular price
-
- Sale price
- £89.99
- Unit price
- per
The WeatherBeeta Waterproof Jackson Jacket is a lightweight but durable hip length multi-seasonal, fully waterproof jacket with concealed, detachable hood. Featuring waterproof zippers, fully taped...







Categories
Clothing

Horse Wear





Stable/Yard/General




Search By Top Brands
-
![files/shires_logo_small_c00581d3-d288-465f-b0db-f3df0bfd3dff.webp]() 50 Item
50 ItemShires
SHOP THE COLLECTION -
![files/Rhinegold_logo_with_horse-_black.jpg]() 50 Item
50 ItemRhinegold
SHOP THE COLLECTION -
![files/weatherbeeta.png]() 50 Item
50 ItemWeatherbeeta
SHOP THE COLLECTION -
![files/charles-owen-logo-icon.png]() 16 Item
16 ItemCharles Owen
SHOP THE COLLECTION -
![files/science_supol_logo_2_250x_bee66ef8-7b88-4e43-9d91-969d73f48897.webp]() 32 Item
32 ItemScience Supplements
SHOP THE COLLECTION -
![files/gallop.png]() 50 Item
50 ItemGallop
SHOP THE COLLECTION -
![files/equine.jpg]() 31 Item
31 ItemEquine America
SHOP THE COLLECTION -
![files/logo.svg]() 19 Item
19 ItemHorseware
SHOP THE COLLECTION -
![files/hy_logo.jpg]() 50 Item
50 ItemHY
SHOP THE COLLECTION -
![files/toggi-logo.jpg]() 27 Item
27 ItemToggi
SHOP THE COLLECTION -
![files/champion_logo.jpg]() 8 Item
8 ItemChampion
SHOP THE COLLECTION -
![files/brogini_logo_000e9841-ec01-485e-9dff-ac1a07cc1387.png]() 10 Item
10 ItemBrogini
SHOP THE COLLECTION -
![files/SP.jpg]() 32 Item
32 ItemSupreme
SHOP THE COLLECTION -
![files/freesteplogo_cb404977-7fdb-40f2-99c0-08ceb77e3a55.png]() 8 Item
8 ItemFreestep
SHOP THE COLLECTION -
![files/dublin_brand.webp]() 42 Item
42 ItemDublin
SHOP THE COLLECTION





